在現代的網路環境中,讓網站被搜尋引擎索引,對於網站的可見性非常重要。但是,並不是所有的網頁都應該被搜尋引擎索引。某些情況下,網站擁有者可能希望特定頁面保持隱私、不公開,或僅供內部使用。這時候,使用 noindex 標籤是一種有效的方式,可以防止這些頁面被搜尋引擎爬蟲收錄進搜尋結果中。
noindex 是一種由網站管理員使用的指令,它告訴搜尋引擎不索引特定的網頁。這個指令可以應用於各種情境,例如開發中的測試頁面、不需要公開的管理後台,或是過期或不再相關的內容。了解如何正確地使用 noindex,不僅能保護網站的隱私,還能優化網站的整體搜尋引擎優化(SEO)策略。
在本文中,我們將介紹使用 noindex 防止網站被索引的幾種主要做法,並說明如何根據不同的需求選擇最適合的方法,確保網站內容得到適當的管理與保護。
- 1 使用 HTML robots meta 標籤
- 2 使用 HTTP 回應標頭 (Response Header)
- 3 使用 robots.txt 文件
- 4 使用 UserAgent 禁止 Robots
- 使用 Search Console (GSC) 測試
- 關於 noindex 標籤的更多知識
- 實際案例
本文章目次
1 使用 HTML robots meta 標籤
最常見的方式是在網頁的 <head> 部分加入 meta 標籤。這個標籤指示搜尋引擎不要索引該頁面。格式如下:
<meta name="robots" content="noindex">
這個標籤可以放在每個你希望被排除在搜尋結果之外的頁面中。除了 noindex 以外,這個寫法還支援同時加入 nofollow 等其他指令,只要用半形逗號分隔
<meta name="robots" content="noindex, nofollow">
您也可以排除特定的搜尋引擎,只要這樣寫
<meta name="googlebot" content="noindex">
<meta name="googlebot-news" content="nosnippet">
可以用的搜尋引擎選項
| 搜尋引擎 (name) | 說明 |
| robots | 所有搜尋引擎 |
| googlebot | Google 搜尋 |
| googlebot-mobile | Google 行動 |
| googlebot-news | Google 新聞 |
| googlebot-image | Google 圖片 |
| googlebot-video | Google 視訊 |
| bingbot | Bing |
| slurp | Yahoo |
| baiduspider | 百度 |
| rogerbot | Moz.com |
| MJ12bot | Majestic.com |
| AhrefsBot | Ahrefs.com |
| ia-archiver | Alexa.com |
可用的行為有這些
| 說明 | |
| all | 沒有索引或服務的限制。注意:這個指令是預設值,如果明確列出這個指令並不會產生任何影響。 |
| noindex | 不在搜尋結果中顯示這個網頁,也不要在搜尋結果中顯示「快取」連結。 |
| nofollow | 不追蹤這個網頁上的連結。 |
| none | 相當於 noindex, nofollow。 |
| noarchive | 不在搜尋結果中顯示「快取」連結。 |
| nosnippet | 不在搜尋結果中顯示這個網頁的文字片段或影片預覽畫面。系統仍會顯示靜態縮圖 (如果有的話)。 |
| notranslate | 不在搜尋結果中提供這個網頁的翻譯。 |
| noimageindex | 不為這個網頁上的圖片建立索引。 |
| unavailable_after: [RFC-850 date/time] | 在指定的日期/時間後不在搜尋結果中顯示這個網頁。指定日期/時間時需使用 RFC 850 格式。 |
注意,這個方法需要你對網站的 HTML 有一定的控制權,適合有能力自行編輯網站代碼的管理員使用。如果想要更詳細 robots meta 的寫法,請參考這篇 Google 文件

2 使用 HTTP 回應標頭 (Response Header)
對於更高級的應用,可以使用 HTTP Header 來實現 noindex 功能。這適用於無法直接修改 HTML 內容的情況,如伺服器自動生成的內容。你可以在伺服器端設置如下的 HTTP Header:
X-Robots-Tag: noindex
Apache .htaccess 寫法
<IfModule mod_headers.c>
Header set X-Robots-Tag "noindex"
</IfModule>
# OR
<IfModule mod_headers.c>
Header setIfEmpty X-Robots-Tag "noindex"
</IfModule>
Nginx 寫法
add_header x-robots-tag "noindex";
PHP 寫法
header('X-Robots-Tag: noindex');
這個方法需要伺服器設置的支持,通常由有伺服器管理經驗的技術人員來執行。此方法特別適合動態生成的內容或是由第三方平台托管的網站。
3 使用 robots.txt 文件
雖然 robots.txt 文件主要用來指導搜尋引擎爬蟲的行為,但也可以用來阻止某些頁面被索引。以下是基本的設定範例:
User-agent: *
Disallow: /example-page/
需要注意的是,這種方式的可靠性相對較低,因為有些搜尋引擎可能會忽略這個設定。因此,robots.txt 更適合作為輔助性手段,而非唯一的防止索引方法。
4 使用 UserAgent 禁止 Robots
可以 UserAgent 偵測,如果是 bot 或 googlebot,就直接讓頁面 404。這樣搜尋引擎就看不到畫面,但是一般瀏覽器使用者可以正常觀看網頁。
下面是一個 PHP 的範例,可以用一些常見的 Browser 套件判斷是否是機器人。這裡推薦 jenssegers/agent
if ($browserKit->isRobot()) {
throw new RouteNotFoundException('Not found', 404);
}
// Show Content
使用 Search Console (GSC) 測試
在 Google Search Console (GSC) 中提供了一個免費的內建工具來測試您的 noindex 標籤。使用 Google Search Console 中的 URL 檢查工具查看 Google 抓取工具在抓取 URL 時是否發現了 noindex 指令。
先在上方看起來像搜尋欄位的「網址檢查」欄,輸入要檢查的網址,然後按下 Enter,再選擇右邊的「測試線上網址」
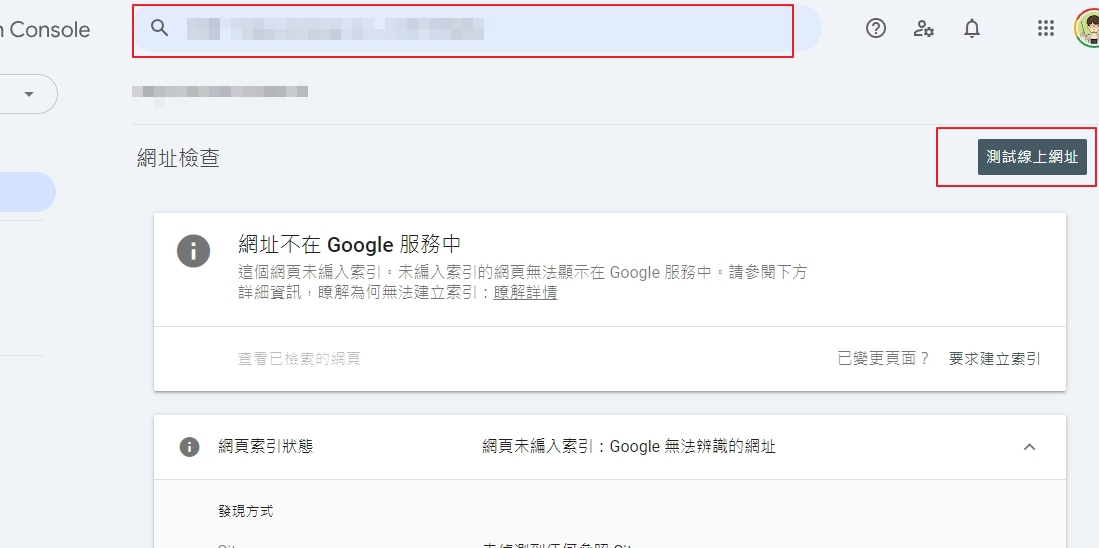
如果像下圖一樣,確實出現 【網頁無法編入索引:遭到「noindex」標記排除】,就表示成功了。
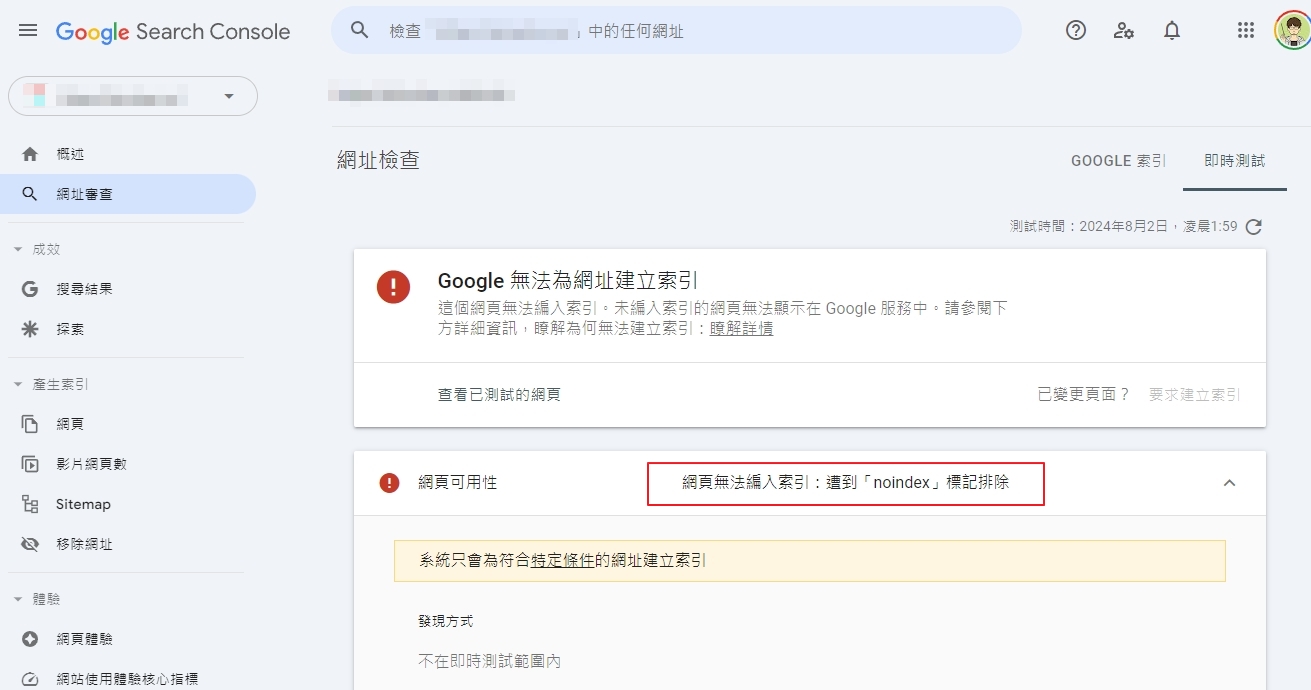
如果您尚未用過 Search Console,也可以參考我們的 Search Console 小白教學全系列


關於 noindex 標籤的更多知識
以下是有關使用 noindex 標籤的一些附加指南及其特性的詳細資訊:
每當您不在程式碼中包含任何 noindex 時,搜尋爬蟲的預設選項是可以為您的頁面建立索引。
注意程式碼中不要出現任何語法錯誤 - 如果語法錯誤,爬蟲將無法理解您的命令,但不會跳出警告給您。
在 HTML 程式碼或 HTTP 回應標頭中新增標記,但不能同時新增兩者。如果各個地方的指令相互矛盾,這樣做可能會產生顯著的負面影響。在這種情況下,Googlebot 將選擇限制索引的指令,換句話說還有可能遭到懲罰。
您可以使用 noimageindex 指令,其運作方式與 noindex 類似,但只會阻止給定頁面上的圖像被索引。
一段時間後,搜雲引擎將開始把 noindex 也視為 nofollow。許多人使用 noindex 停用頁面索引,但將其與 follow 指令結合使用,認為這樣可以讓爬蟲仍然抓取頁面上的連結。但Google解釋說,
noindex, follow指令最終將被視為noindex, nofollow,因為在某些時候,他們會停止抓取無索引頁面上的連結。因此,連結目標頁面可能不會被索引,並且排名可能會下降,這可能會對網站產生負面影響。減少在 robots.txt 檔案中使用 noindex。儘管搜尋引擎機器人仍遵循 robots.txt 檔案中的 noindex 指令。然而她一直都不是標準方案。截至 2019 年 9 月,Google 宣布已停用處理 robots.txt 檔案中不受支援和未發布的規則的程式碼(例如 noindex)。
實際案例
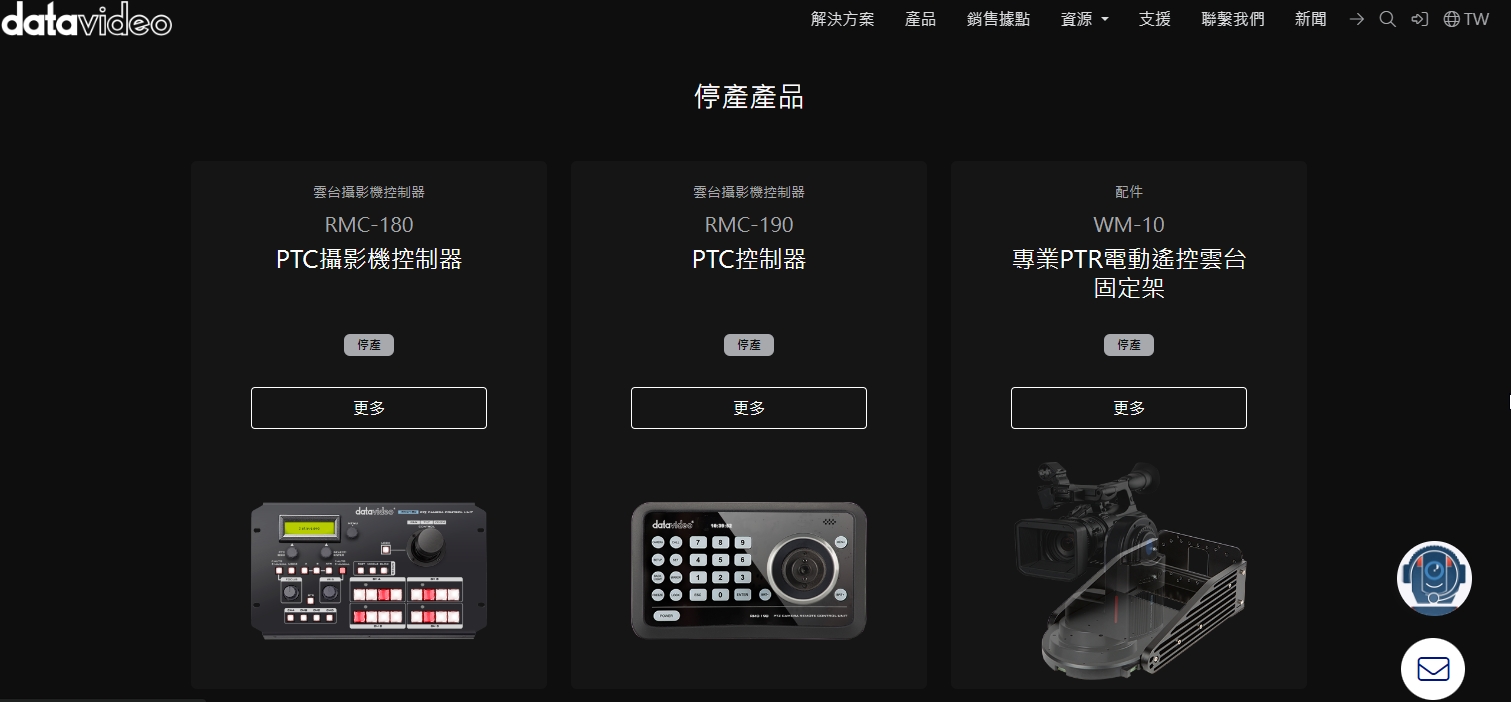
夏木樂介紹一個實際案例,Datavideo 網站中,有大量的停產產品頁面。這些產品雖然停產了,但是頁面會保留下來,讓已經購買產品的使用者,可以用站內搜尋找到該產品,然後下載相關的文件與支援軟體。
但是 Datavideo 希望只有站內搜尋能找的到那些停產產品,但不要被 Google 索引,不然會有大量消費者一直打電話詢問可否購買。
於是夏木樂替 Datavideo 製作了 noindex 的功能,讓 Google 停止索引這些停產網址,但是以購買的消費者依然可以從網站上找到這些產品並取得資源。
如果您的網站也需要根據策略來阻擋搜尋引擎,夏木樂很樂意為您規劃網站的 SEO 技術規格與策略,歡迎聯繫我們。
另外也可以參考我們的其他文章: